马尔科夫蒙特卡洛采样方法
概述
- 马尔科夫链
- MCMC采样
- Metroplis-Hasting算法
马尔科夫链
在维基百科上关于马尔科夫链的定义如下
马尔可夫链是满足马尔可夫性质的随机变量序列X1, X2, X3, …,即给出当前状态,将来状态和过去状态是相互独立的.从形式上看,如果两边的条件分布有定义(即如果 则
$X_i$的可能值构成的可数集S叫做该链的”“状态空间”.通常用一系列有向图来描述马尔可夫链,其中图n的边用从时刻n的状态到时刻n+1的状态的概率 $Pr(X_{n+1}=x\mid X_{n}=x_{n})$ 来标记.也可以用从时刻n到时刻n+1的转移矩阵表示同样的信息.但是,马氏链常常被假定为时齐的,在这种情况下,图和矩阵与n无关,因此也不表现为序列.
下面是网上的一个例子
马氏链的一个具体的例子。社会学家经常把人按其经济状况分成3类:下层(lower-class)、中层(middle-class)、上层(upper-class),我们用1,2,3 分别代表这三个阶层。社会学家们发现决定一个人的收入阶层的最重要的因素就是其父母的收入阶层。如果一个人的收入属于下层类别,那么他的孩子属于下层收入的概率是 0.65, 属于中层收入的概率是 0.28, 属于上层收入的概率是 0.07。事实上,从父代到子代,收入阶层的变化的转移概率如下
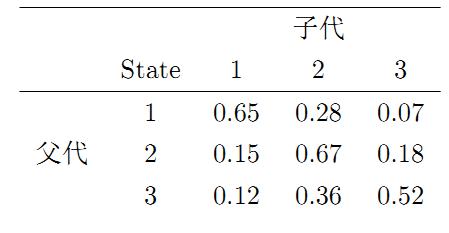
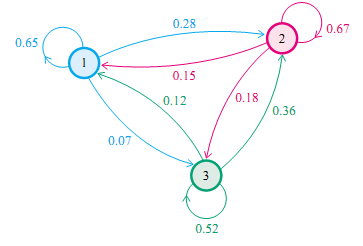
使用该状态转移概率矩阵,从任意一个随机概率分布开始,不断迭代进行状态转移,最终为稳定收敛到概率分布[ 0.28650138, 0.48852158, 0.22497704]
演示代码如下
import numpy as np
import scipy as sp
# transition probability matrix
P = np.array([[0.65,0.28,0.07], [0.15, 0.67, 0.18], [0.12,0.36,0.52]])
# initial probability
pi = np.random.uniform(0.0,1.0,3)
# normalize to sum(pi) = 1
pi = pi / sum(pi)
# start to iteration and print distrubition which can show convergence
iter = 0
print iter,pi
while iter < 50:
pi = np.matmul(pi,P)
iter += 1
print iter,pi
稳定分布与特征向量的关系
稳定分布π是一个(行)向量,它的元素都非负且和为1,不随施加P操作而改变,定义为
矩阵特征向量与特征值的定义
在数学上,特别是线性代数中,对于一个给定的线性变换A,它的特征向量(eigenvector,也译固有向量或本征向量) v 经过这个线性变换[1]之后,得到的新向量仍然与原来的 v 保持在同一条直线上,但其长度或方向也许会改变。即 $\lambda$为标量,即特征向量的长度在该线性变换下缩放的比例,称 $\lambda$ 为其特征值(本征值).
对比定义可以看出,这两个概念是相关的,并且 $\pi = \frac{e}{\sum_{i}{e_{i}}}$ 是由( $\sum_{i} pi_{i}=1$ )归一化的转移矩阵P的左特征向量 e的倍数,其特征值为1.
操作上:
- 对P的转置进行特征值分解得到特征向量和特征值.
- 最大的特征值应为1,其对应的特征向量为矩阵的第i列
- 对特征向量进行归一化,可以得到该状态转移矩阵的稳定分布
演示代码如下
# evd
w,v=np.linalg.eig(P.transpose())
# there must be an eigenvalue w[i] should be 1.
# all abs(eigenvalue) <= 1
# correspond eigenvector is the column of v[:,i]
# the eigenvector should be normalized to 1 as it should be probability distribution
idx = np.where(abs(w-1.0)<1e-9)[0][0]
print w[idx]
print v[:,idx]/sum(v[:,idx])
实际上nxn矩阵特征向量的一种求法就是用一个随机向量不断迭代与该矩阵相乘
可反转马尔可夫链(细致平稳条件)
可反转马尔可夫链类似于应用贝叶斯定理来反转一个条件概率:
以上就是反转的马尔可夫链。因而,如果存在一个 $\pi$,使得:$\pi_{i}p_{ij}=\pi_{j}p_{ji}$ 那么这个马尔可夫链就是可反转的. 这个条件也被称为细致平衡(detailed balance)条件. 对于所有的i求和:
所以,对于可反转马尔可夫链,$\pi$ 总是一个平稳分布。
注: 细致平稳条件为马尔可夫链有平稳分布的充分条件
MCMC 采样
下面的代码展示了一个简单的基于马尔科夫链的采样, 用到马尔科夫链和1次inverse cdf.
import numpy as np
# transition probability matrix
P = np.array([[0.65,0.28,0.07], [0.15, 0.67, 0.18], [0.12,0.36,0.52]])
# states
states = [0,1,2]
samples = [0]
for i in range(49999):
samples.append(np.random.choice(states, 1, p=P[samples[-1]])[0])
print "the actual distribution"
print [samples.count(0)/50000.0,samples.count(1)/50000.0,samples.count(2)/50000.0]
# the stationary distribution
# evd
w,v=np.linalg.eig(P.transpose())
idx = np.where(abs(w-1.0)<1e-9)[0][0]
print "expected distribution"
print v[:,idx]/sum(v[:,idx])
一般实践中,马尔科夫链的采样需要找到满足细致平稳条件(这是个充分条件)的状态转移概率矩阵. 有时这个不好找.
设$\pi(x)$为目标分布, 马尔科夫状态转移概率矩阵为Q, 如果此时细致平稳条件不成立,即
可以对Q进行改造以满足细致平稳条件, 具体方法为引入 $\alpha$, 使下式成立.
当下面两式成立时,上式可成立
这样,我们就得到了我们的分布π(x)对应的马尔科夫链状态转移矩阵P,满足:
有了状态转移概率,现在我们可以开始做采样了
- $\pi$为样本的目标概率分布
- P为状态转移概率分布,也就是$P(x_t=j \vert x_{t-1}=i)$
- Q为推荐的采样分布(方便采样的分布),
- $\alpha$ 概率, 为了使 $Q(i,j)\alpha(i,j)$ 满足细致平稳条件. 一般来说$Q(i,j)\alpha(i,j)$ 也是不方便直接采样的. 实际的做法是采用拒绝采样方法,把 $\alpha(i,j)$ 看作一个状态转移的接受概率. 从(0,1)均匀分布中做一个采样得到u,如果 $u \le \alpha(i,j)$ 则接受 $Q(i,j)$ 采样出样本的状态转移,否则拒绝.保持原状态.
具体的方法如下,下面表述中用 $x_{t-1},x_t$ 代替i,j
- 从任意简单概率分布采样得到初始状态值 $x_0$
- 从推荐条件概率分布$Q(x \vert x_{t-1})$ 中采样得到样本 $x_t$
- 从均匀分布采样u∼uniform[0,1]
- 计算接受概率 $\alpha(x_{t-1},x_t) = \pi(x_t)Q(x=x_{t-1} \vert x=x_t)$
- 重复步骤2,3,4直到采样到足够的样本
Q分布的选择,对于连续随机变量,个人觉得高斯分布是个常用的选择.也就是t时刻的值为以t-1时刻的值为均值的高斯分布.
一个演示示例
- 目标平稳分布是一个均值2,标准差3的正态分布
- 马尔科夫链状态转移矩阵Q(i,j)的条件转移概率是以i为均值,方差1的正态分布在位置j的概率密度值
代码如下
import random
from scipy.stats import norm
import matplotlib.pyplot as plt
T = 100000
pi = [0 for i in range(T)]
sigma = 1
t = 0
while t < T-1:
t = t + 1
pi_star = norm.rvs(loc=pi[t - 1], scale=sigma, size=1, random_state=None)
alpha = norm.pdf(pi_star[0], loc=3, scale=2)*norm.pdf(pi_star[0],loc=pi[t-1],scale=sigma)
u = random.uniform(0, 1)
if u < alpha:
pi[t] = pi_star[0]
else:
pi[t] = pi[t - 1]
plt.scatter(pi, norm.pdf(pi, loc=3, scale=2))
num_bins = 50
plt.hist(pi, num_bins, normed=1, facecolor='red', alpha=0.7)
plt.show()
产生100000样本的直方图如下
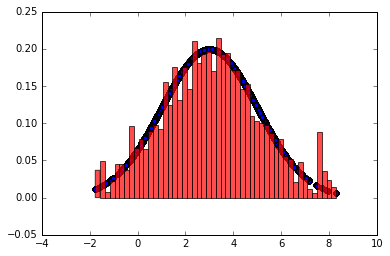
看上去还行, 是吗? 其实有问题,如果只做5000个样本, 你会得到下面的图形
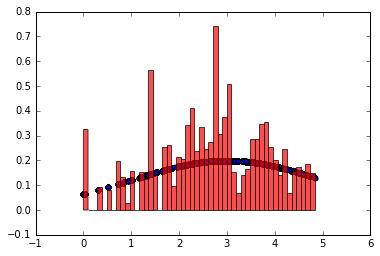
除此之外,如果打印样本的值,你会发现有连续几十个采样值是一样的. 即使采样100000个样本,直方图看上去还行,其采样值大多是不好用的.
问题的原因出在接受概率$\alpha$过小,导致大量重复值过多.
一个直接的改进是:
- 进行大量样本的采样
- 对采样结果每隔n的样本取一个有效样本
例如取200000万个样本,然后每40个样本取一个有效样本, 代码与图形如下
reduced_pi = [pi[i] for i in range(0,T,40)]
plt.scatter(reduced_pi, norm.pdf(reduced_pi, loc=3, scale=2))
plt.hist(reduced_pi, 50, normed=1, facecolor='red', alpha=0.7)
plt.show()
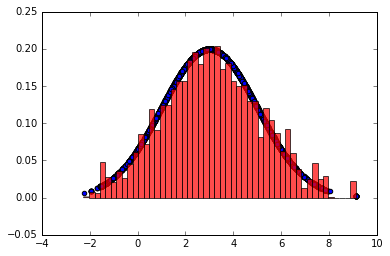
这样做还是浪费了大量的计算,每n个样本才产生1个有效样本, 有更好的方法吗? 有
Metroplis-Hasting算法
M-H算法主要是解决接受率过低的问题, 回顾MCMC采样的细致平稳条件:
我们采样效率低的原因是 $\alpha(i,j)$ 太小了,比如为0.1,而 $\alpha(j,i)$ 为0.2. 即:
这时我们可以看到,如果两边同时扩大五倍,接受率提高到了0.5,但是细致平稳条件却仍然是满足的,即:
这样我们的接受率可以做如下改进,即:
在MCMC的基础上,只需将第4步中的计算接受率的公式改为上式即可.
代码与图形如下
# alpha = norm.pdf(pi_star[0], loc=3, scale=2)*norm.pdf(pi_star[0],loc=pi[t-1],scale=sigma)
alpha_ij = norm.pdf(pi_star[0], loc=3, scale=2)*norm.pdf(pi_star[0],loc=pi[t-1],scale=sigma)
alpha_ji = norm.pdf(pi[t-1], loc=3, scale=2)*norm.pdf(pi[t-1],loc=pi_star[0],scale=sigma)
alpha = min(alpha_ij/alpha_ji,1)
直接用MH算法产生10000个样本图形
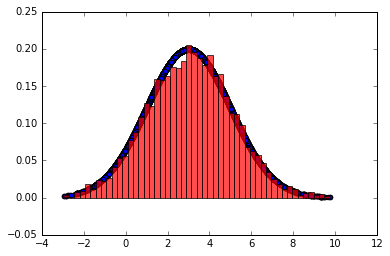
- 出现1599次连续采样值相同.
- 如果采用每2个样本取1个有效样本, 仍然有139次连续样本值相同
- 如果采用每3个样本取1个有效样本, 仍然有16次连续样本值相同
- 如果采用每4个样本取1个有效样本, 仍然有2次连续样本值相同
- 如果采用每5个样本取1个有效样本, 没有连续样本值相同
注: 若Q分布对称,即Q(i,j)=Q(j,i), 接受率 $\alpha$ 的计算可进一步简化
参考
https://ccjou.wordpress.com/2009/08/06/%E9%A6%AC%E5%8F%AF%E5%A4%AB%E9%81%8E%E7%A8%8B/
https://zh.wikipedia.org/wiki/%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E9%93%BE
http://www.cnblogs.com/pinard/p/6638955.html