基本的蒙特卡洛采样方法
概述
本文介绍基本的蒙特卡洛采样方法.
- 拒绝采样
- 自适应拒绝采样
- 重要性采样
拒绝采样
方法简介
拒绝采样采用蒙特卡洛方法. 对于一个随机变量的分布p,如果分布p不方便进行直接采样,那么给出一个便宜采样的建议分布q,同时一个数M.满足下列不等式
从建议分布q上进行采样得到一个样本,设为$x_i$, 此时需要决定是否接受还是拒绝这个样本,该样本被接受的概率为 $\frac{p(x_i)}{Mq(x_i)}$. 具体的做法为,从[0,1)区间的均匀分布中采样得到一个样本 $u_i$, 若 $u_i <= \frac{p(x_i)}{Mq(x_i)}$ 则接受该样本,否则拒绝该样本.
Beta分布的拒绝采样
下面以Beta分布为例, Beta分布有参数a,b,决定了分布pdf的形状. 而Beta分布pdf的自变量实际是Bernoulli实验的成功概率. Beta分布也是二项分布的共轭先验分布. 所以Beta分布的样本空间被限制在[0,1]区间. 而一个最简单方便的推荐分布q就可以是[0,1]区间的均匀分布.
Beta分布的pdf
当a=3,b=6时Beta分布的pdf图形如下,对x求导设为0求解得到当x=2/7时有最大值.最大值约为2.54
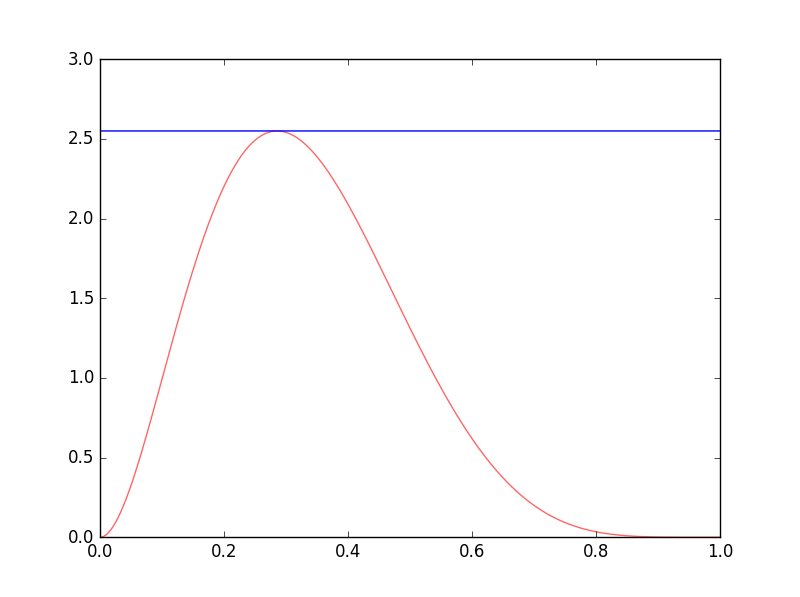
# beta distribution with shape parameter a=3,b=6
a=3
b=6
# just show max value should be at 2.0/7 and max value is ceilled to 2 decimal points
beta_max = round(beta.pdf(2.0/7,a,b) + 0.005, 2)
# plot beta distribution
x = np.linspace(0.0,1.0,50000*beta_max)
plt.plot(x, beta.pdf(x, a, b),'r-', lw=1, alpha=0.6, label='beta pdf')
plt.plot(x,(np.ones(len(x)) * beta_max).tolist())
plt.show()
对应拒绝采样方法,q(x)为0,1区间上的均匀分布,M为上面代码中的beta_max.
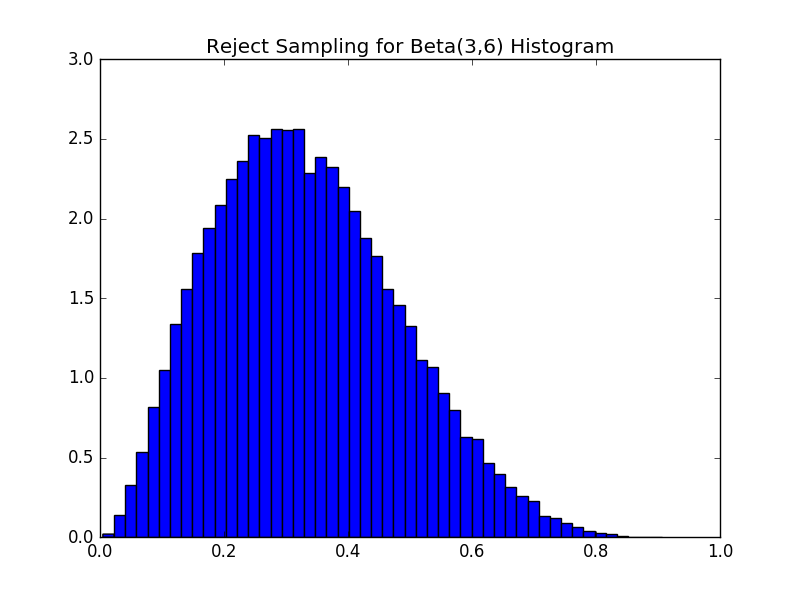
下列代码为采样过程的代码
# random sampling 50000 on uniform in [0,1)
uni_samples = np.random.uniform(0.0,1.0,50000*beta_max)
# calculate "accept probability" = beta.pdf(x) / beta_max
# then do another uniform sample, if sample < beta.pdf(x) / beta_max,
# we accept the x as an sample from beta(3,6).
beta_samples = uni_samples[np.random.uniform(0.0,1.0,len(x)) < beta.pdf(uni_samples,a,b) / beta_max]
plt.hist(beta_samples, bins=50,normed=True)
plt.title("Reject Sampling for Beta(3,6) Histogram")
plt.show()
小结
方法简单,对于Beta分布来说,推荐分布和相对应的M很好找. 对于上面的例子来说样本的接受率为1/beta_max 缺点是有很大多分布的推荐分布和M不好找,有时即使能找到,但是接受率可能过小
自适应拒绝采样方法
如果对于某个复杂的分布,直接找一个简单的推荐分布q和M,有时会导致采样接受率过低从而导致大量样本被拒.
有一个的漂亮的思路是用分段的直线将分布p包络起来进行采样.
用分段直线进行包络时,如果分布曲线是凹的(开口向下,concave),那么该曲线上的点的切线都将在该曲线的上方.于是在该曲线上找若干个点,并用这些点的切线,就可以将该曲线包络住.
大多数分布都具有指数的形式,不一定是凹函数,取对数后分布形式会变的简洁易于找切线.此时对分布的要求就转为取对数后是凹函数即可.
总体步骤如下
- 给出分布函数pdf的对数函数f(x)=log(p(x)),及其对应的一阶导数函数f’(x)
- 给定几个初始点,求出这几个初始点的切线,并计算切线与切线的交点.如果有边界,边界一般为垂直于横轴的直线,要计算切线与边界的交点.
- 将分段直线取指数转换为对应的指数曲线, 分别计算各段指数曲线的定积分.也就是计算各段曲线下覆盖的面积.累积且归一化后得到一个分段cdf.
- 从均匀分布中得到一个样本,记为y,用inverse cdf的方法根据分段cdf找到样本属于那一段.
- 再用该段对应的指数函数的cdf,再次使用y,用inverse cdf找到对应的x的值.
- 再次用均匀分布(0,1)中产生一个随机值,若该随机值小于等于p(x)/e(x)则接受该样本x. e(x)为该段对应的指数函数.
- 若第6步中样本x被拒,则将x点加入到初始点集合中,重复2,3步,也就是多加一段以形成更好的包络.
在采样过程中用到两次inverse cdf,和一个拒绝采样.
Beta分布的自适应拒绝采样的示例
第一步
Beta分布函数pdf,对应的对数函数f(x)=log(p(x)),及其对应的对数函数一阶导数函数f’(x). 代码如下
注意,这里我去掉了Beta分布的常系数项
import numpy as np
import matplotlib.pyplot as plt
def beta_pdf(x,a=3,b=6):
return np.power(x,(a-1))*np.power((1-x),(b-1))
def f(x, a=3, b=6):
"""
Log beta distribution
There is constant has been remove which is gamma(a+b)/(gamma(a)+gamma(b))
"""
return (a-1)*np.log(x)+(b-1)*np.log(1-x)
def fprima(x, a=3, b=6):
"""
Derivative of Log beta distribution
"""
return (a-1)/x-(b-1)/(1-x)
第二步
给定几个初始点,求出这几个初始点的切线,并计算切线与切线的交点.如果有边界,边界一般为垂直于横轴的直线,要计算切线与边界的交点.
Beta分布有边界0和1. 在示例中我给出3个点,那么一共有3个切线,两个边界,我们关心的焦点就有4个.这四个交点在横轴上,记为z.纵轴上,记为u
代码如下
# 初始点
x = np.array([0.1,0.4,0.8])
# 初始化交点的横轴对应的值
z = np.zeros(len(x)+1)
z[0] = 0.0
z[-1] = 1.0
# 计算切线交点对应的横轴的值
# use np.diff function will give more simple code.
for j in range(len(x)-1):
z[j+1] = (f(x[j+1])-f(x[j]) - x[j+1]*fprima(x[j+1]) + x[j]*fprima(x[j])) / (fprima(x[j]) - fprima(x[j+1]))
# 计算切线交点对应的纵轴的值
# h log pdf, hprime, the deriative of h
h = f(x)
hprime = fprima(x)
# the upper bound line function, which are piecewise liines,
# u(x) = h(x[j]) + (x-x[j])hprime(x[j])
# we only calculated the intersect points upper bound.
u = hprime[[0]+range(len(x))]*(z-x[[0]+range(len(x))]) + h[[0]+range(len(x))]
# 画出对应的pdf的对数曲线,切线,并标注交点
# plot log beta distribution
fig, ax = plt.subplots()
log_x = np.linspace(0.0,1.0,1000)
ax.plot(log_x,f(log_x))
# plot tangent lines
for i in range(len(x)):
log_line_x = np.linspace(z[i],z[i+1],30)
log_line_y = h[i] + hprime[i]*(log_line_x-x[i])
ax.plot(log_line_x,log_line_y,color='green')
# mark x-axis points, i.e. x and z
xticks = []
xticklabels = []
for i in range(len(x)):
ax.plot([x[i]]*30,np.linspace(-35,0,30),ls='dotted',color='red')
xticks += [x[i]]
xticklabels += ["x[%d]"%i]
for i in range(len(z)):
ax.plot([z[i]]*30,np.linspace(-35,0,30),ls='dotted',color='red')
xticks += [z[i]]
xticklabels += ["z[%d]"%i]
ax.set_xticks(xticks)
ax.set_xticklabels(xticklabels)
# mark y-axis points, i.e. u
ax.scatter(z,u,color='blue')
fig.show()
图像如下
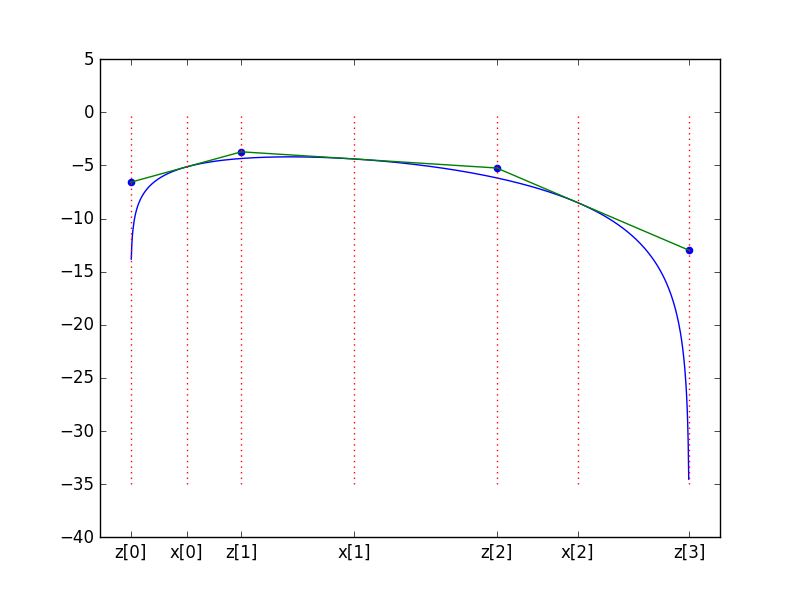
第三步
将分段直线取指数转换为对应的指数曲线, 分别计算各段指数曲线的定积分.也就是计算各段曲线下覆盖的面积.累积且归一化后得到一个分段cdf.
例子中的第一段的积分公式如下
在本例中f函数为去除常系数的beta(3,6)分布的对数函数, f’为对应的一阶导数函数
对于积分有
于是第一段的积分结果为
其中 $u_0 = f(x_0)+f(z_0-x_0) * f’(x_0)$, $u_1 = f(x_0)+f(z_1-x_0) * f’(x_0)$
其余各段同理可求的相应定积分结果并累积记为s, 对s进行归一化得到cdf, 代码如下
s = np.hstack([0,np.cumsum(np.diff(np.exp(u))/hprime)])
cu = s[-1]
cdf=s/cu
第四步,第五步,第六步
从均匀分布中得到一个样本,记为y,用inverse cdf的方法根据分段cdf找到样本属于那一段.
再用该段对应的指数函数的cdf,再次使用y,用inverse cdf找到对应的x的值.
再次用均匀分布(0,1)中产生一个随机值,若该随机值小于等于p(x)/e(x)则接受该样本x. e(x)为该段对应的指数函数.
我合并到一个函数中,代码如下
def inverse_and_test(y):
'''
for an uniformed sample y, use inverse cdf get sample xt
1. inverse piece-wised cdf to get piece
2. on that piece, inverse cdf to get x
'''
# Find the largest z such that cdf < y. i.e. inverse piecewise cdf get piece
i = np.nonzero(cdf < y)[0][-1]
# Figure out x from inverse cdf in relevant piece
xt = x[i] + (-h[i] + np.log(hprime[i]*(cu*y - s[i]) + np.exp(u[i]))) / hprime[i]
ut = h[i] + (xt-x[i])*hprime[i]
ht = f(xt)
if np.random.uniform() < np.exp(ht-ut):
return xt
第七步
略去
最后进行采样并画图
代码如下
uni_samples = np.random.uniform(0.0,1.0,50000)
beta_samples = filter(lambda x: x is not None,map(inverse_and_test,uni_samples))
# plot sampling result
fig, ax = plt.subplots()
ax.hist(beta_samples, bins=50,normed=True)
fig.show()
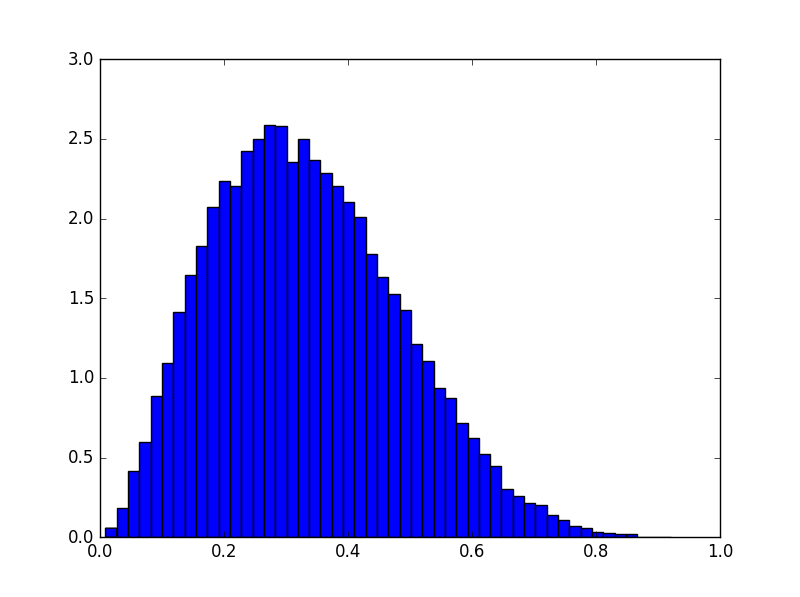
小结
注意,对于例子中这个Beta(3,6)分布来说,尽管使用自适应拒绝采样可以大大提高接受率,但是在采样过程中要用到两次inverse cdf和一个拒绝采样.每次采样的操作成本还是很高的.从耗时上来说直接做拒绝采样速度反而快
ARS有两种方式,我只阐述了基于切线方式的ARS.也就是要用到1阶导数. 还有一种方式是免求导的.
对于非log concave的分布来说,可以与Metropolis Hasting方法结合使用.
同时对多变量分布的采样可以与Gibbs Sampling结合使用.
重要性采样
很多应用想从复杂概率分布中采样的一个主要原因是计算期望. 重要采样(importance sampling)的方法提供了直接近似期望的框架,但是它本身并没有提供从概率分布 p(z) 中采样的方法。
所以请注意,最后样本点分布不能服从p(z)分布!!
重要性采样与接受-拒绝采样有异曲同工之妙. 接受拒绝采样时通过接受拒绝的方式对通过q(z)得到的样本进行筛选使得最后得到的样本服从分布p(z),每个接受的样本没有高低贵贱之分,一视同仁. 而重要性采样的思想是,对于通过q(z)得到的样本全部都被接受!但是全部接受后,每个样本都会被附一个重要性权重,有了样本和权重后,是可以计算期望的.但是生成的样本并不服从p(z)的分布.
P(X)不方便采样,但是Q(X)方便采样,用Q(X)分布进行采样, 每个样本有重要性权重 P(X)/Q(X), 再用Q(X),可以计算期望.
参考
http://www2.stat.duke.edu/~cnk/Links/slides.pdf
https://github.com/alumbreras/ARS