贝叶斯网络结构学习1
说明
本文为Coursera课程probability graphic model的学习笔记
Baysian Network Structure Learning Overview
目标
给定一组随机变量,如果用贝叶斯网络来表达相互独立或依赖关系,一般需要该领域专家协助. 问题是
- 专家也未必能完全标识出所有的关系.
- 需要解决的问题本身就是发现网络中的相互关系
所以需要进行贝叶斯网络结构的学习,而不仅仅是在已知结构的情况下进行概率推断
结构学习的准确性问题
考虑下图所示的情况
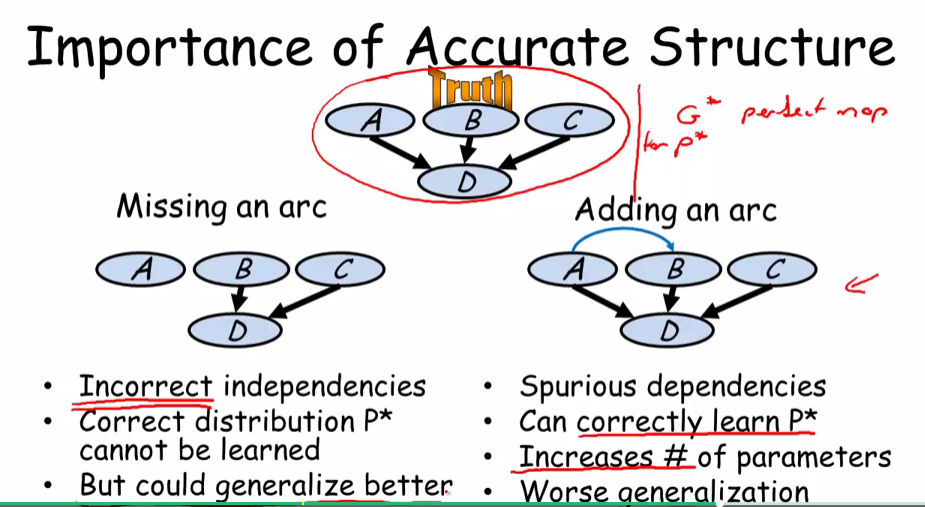
图中展示了学习到的结构与真实结构不相同的两种情况
- 缺失了一个依赖关系
- 这种情况实际上也就是引入了一个不正确的独立关系
- 在后续的参数学习中将不能学习到正确的分布
- 但是学习的参数少,虽然模型表达能力弱有欠拟合的风险,但是不会有过拟合的问题.在仅有小数据量训练时,模型的泛化能力比较好.也就是在测试数据上的性能可能还不错
- 多了一个额外的依赖关系
- 在后续的参数学习中将能学习到正确的分布
- 模型的参数增多
- 在小数据量训练时,泛化能力弱
基于打分的结构学习
对于不同的结构如何评判好坏的问题.
可以使用打分的机制,定义一个打分函数来评估结构和训练数据的匹配程度,实际上等同于机器学习中的代价函数.这一步将一个学习问题转换为一个优化问题
在优化过程中在进行搜索来找到一个结构能最大化得分.
似然打分函数 likelihood score
一个贝叶斯网络包含有结构G的问题,同时在给定结构后还有该结构的网络参数 $\theta$ 问题(例如在具有依赖关系的情况下的条件概率分布参数)
在使用似然打分的情况下,问题就是找到G和 $\theta$ 能最大化下面的似然函数
$\hat\theta$ 为给定结构g和数据D时参数的最大似然估计值
一个例子
下图展示了一个最简单的结构图的例子,两个随机变量X,Y. 在结构$g_0$中X,Y相互独立,而在结构$g_1$中Y依赖于X.

- $x[m],y[m]$ 在离散的情况下,x和y的第m个取值.
- $M[x,y]$ 为给定x,y的值时,在数据集D中该联合事件一共发生的次数, 为一个充分统计量
从上面的例子分析可以看出,对于结构$g_1$,由于增加了一个依赖关系其似然分大于等于结构$g_0$的得分.多出来的得分为X,Y的互信息量. 这个互信息量$0<=I(X;Y)<=1$, 本质上互信息度量X和Y共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度. 如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息, 互信息为0, 如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,互信息为最大值1.
很显然, 这个互信息越大,我们越应当建立X,Y之间的依赖关系. 但同时,需要注意互信息总是大于0的.所以在结构学习时需要权衡. 如果总是简单的最大化似然得分,则会倾向于建立一个全连接的网络
样例分析的一般化

$I_{\hat{P}}(X_i;Pa_{x_i}^G)$ 为在结构图G中节点$X_i$与其父节点的互信息量
从公式可以看出节点$X_i$与父节点越相关,得分越高
用似然函数打分的局限性
如前所述, 互信息总大于0, 在最大化似然函数时会倾向于全连接网络,会导致过拟合
解决的方法一般为加正则项,对模型的复杂度在打分时进行惩罚,
- 显示的进行惩罚,如打分时对总体的父节点数,或者总体参数进行惩罚
- 采用baysian方法,用先验概率分布来防止过拟合
BIC Score 贝叶斯信息准则打分
前面已经讨论了用似然函数计分的局限性,这里谈论用BIC方法来防止过拟合的问题
M为训练样本数量,Dim[g]为模型g的独立参数个数,连接越多参数越多.同时BIC Score也可以被写为下面的式子
如前所述,似然分为所有节点与其父节点之间的互信息减去所有节点的熵. 值得注意的是当样本数量M增大时,似然分随M线性增长,而惩罚项则是对数增长. 所以当样本数量M趋近于无穷大,BIC socre会使模型更好的适应于数据. M为logM的高阶无穷大
当M趋于无穷大时,真实的模型结构 $ G^* $ 或其相应的独立等价结构(I-equivalent structure)能最大化BIC Score,原因如下
- 任何多余的连接在M趋于无穷时将不能提升似然得分,但是确会受到惩罚.
- 任何被需要的连接其似然得分随M线性增长,而惩罚为对数增长,所以M足够大时,似然得分大于惩罚.需要的连接会被加上.
最后,惩罚项的由来请看下一节
Baysian Score
基本定义公式
于是有
值得注意的是关于给定模型g得到数据D的条件概率,在用似然打分函数时,模型的参数$\theta$,直接取最大似然估计的值. 而在贝叶斯计分时,遵循所有的不确定性都应当用概率分布来表示,所以需要用边缘似然marginal likelihood. 公式如下
对于离散变量组成的贝叶斯网络, 其边缘似然函数如下
简单说明,
- $X_i$ 为结构中第i个节点, 所以第一个连乘表示为所有的节点计算
- $Val(Pa_{X_i}^g)$ 为给定结构g节点$X_i$的所有父节点
- $Val(X_i)$ 为节点$X_i$的所有可能的取值
边缘似然函数
考虑一个单变量的情况,已抛硬币为例设抛了5次硬币为{H,T,T,H,H},参数的最大似然估计为
M为实验总次数,也就是5,M[1]为出现H的次数,也就是3,M[0]为出现T的次数为2.在上面的例子中,实际上等同于先似然估计出现H的概率为3/5=0.6,出现T的概率为2/5=0.4,然后估计出联合事件{H,T,T,H,H}的概率为
而使用Chain Rule来计算联合事件的概率为
实际上是根据前面的数据估计出参数的概率分布,注意是概率分布,不是估计出最大似然的参数,然后计算联合概率分布并对参数分布进行积分. 由于这个积分所以被称为边缘似然.
回到前面的例子, 对于事件{H,T,T,H,H}当第一个H出现时,对参数的估计采用beta(1,1)分布作为参数的先验分布, 第一,估计出该事件的概率, 第二,计算后验分布,更新beta分布的参数以用作下个事件的先验分布.
Beta 分布回顾
令
有
针对前面的例子数据D每次只包含一个事件,结果为H或T. Beta参数更新方法为
- 若结果为H, $\alpha = \alpha + 1$
- 若结果为T, $\beta = \beta + 1$
回到例子,计算{H,T,T,H,H}的概率
- $\alpha = 1, \beta = 1$
- $P(X_1=H) = \frac{1}{2}$
- $\alpha = 2, \beta = 1$
- $P(X_2=T \vert X_1=H) = \frac{1}{3}$
- …
写成一个式子即为
最后结果为
多变量的边缘似然函数
上面简单描述了单变量的边缘似然函数,在贝叶斯网络中实际要考虑的是多变量的问题,隐参数不仅仅是变量的概率分布参数,还有一个网络结构的问题(也就是变量间相互依赖关系), 不同的网络结构会有不同的分布参数需要被估计
在两个随机变量X,Y的情况下,边缘似然函数为
考虑两种不同的网络结构
- X,Y相互独立
- X->Y
X,Y相互独立时, 假设分布参数 $\theta_X, \theta_Y$ 相互之间独立,可以将上述的边缘概率分布分解成两项.
X -> Y的情况下, 设X的取值只为{0,1}的二项情况, 如果分布参数(即 $\theta_X, \theta_{Y \vert X^0}, \theta_{Y \vert X^1}$ )相互之间仍然独立则可以可以将上述的边缘概率分布分解成
先验分布
网络结构的先验分布
一般来说结构在计分中扮演的角色为次要,可以设结构的先验分布为均匀分布.即每种不同的结构在初始先验分布时为相同概率, 但训练样本较少时不同的结构先验分布还是不同的结果,可以将我们的偏好加入到先验分布中去.譬如先验分布的概率正比于网络结构中连接数量的指数函数 $P \propto C^{\vert g \vert}, \vert g \vert$为连接数量
分布参数的先验
K2 Prior
一个简单的做法是对所有的参数取固定的Dirichlet分布,如变量Y(可取0,1)可以设Dirichlet(1,1)分布为先验.这种先验也称为K2(Kutato) Prior. 可以工作,但更好的一个做法是取BDe(Bayesian Dirichlet equivalence)先验.
K2先验的不一致性, 当二项变量Y独立时,先验分布$Dirichlet(1,1)$, 当其依赖于四项变量X时, 需要考虑 $\theta_{y \vert x^i}$ 的先验分布,这样实际上是有了两套分布参数,每套分布参数有4个.在统计累积样本是一共有8个不同样本累积. 这样Y独立和Y非独立时是不一致的.
BDe Prior
BDe先验的做法与前面所谈到的边缘概率分布参数估计的方法一致, 首先用提取一个先验概率分布,然后计算等效的参数 $\alpha$ .
针对前面的例子 $\theta_{y \vert x^i}$, 对应的参数 $\alpha_y$ 计算方法为
在上面的例子中$P^\prime$代表了网络结构的先验分布.
BDe 与 BIC
当训练样本数M趋于无穷大时, 一个采用Dirichlet先验分布的网络满足下列等式
可以看出与BIC Score是一致的,两者仅差了一个常数项,该常数项与样本数m无关
网络结构的分解
网络可能的结构形式是节点数的超指数分布.计算量非常大,为了简化计算
结构先验需要满足structure modularity,即 $P(G)$ 能分解成为几个 family 上的乘积,并且 I-equivalent class 具有相同的 prior. 这点在实践中很重要,
而参数先验是需要可被分解的. 换言之,节点的CPD仅依赖于局部结构即只与该节点之父节点相关
这样, 区别的结构变动将只需要更新局部的计算.
Likelihood Score是满足网络可以分解的.
对于Baysian Score, 满足下列条件是是可以分解的.
- 设g为网络结构, P(g)为网络的结构先验,这个先验满足结构可分解,
- $P(\theta \vert g)$ 为满足全局独立且可以模块化
对于上文谈到的网络结构和参数的先验都是可以分解的
Baysian Score 小结
- Bayesian score使用先验概率,且计算边缘似然,避免了过拟合
- 参数先验常使用BDe prior
- BDe prior需要使用网络结构的信息
- 能自然的使用先验知识
- 独立等价(I-equivalent)网络会有相同的分数
- Bayesian score 与 BIC
- 当样本数趋于无穷时,两者一致
- Baysian score当样本数趋于无穷时能学习到正确的网络
- BIC 当样本数少时,会欠拟合
参考
Probability Graphic Model, by Daphne Koller,…