word2vec简介
概述
word2vec词向量是嵌入技术的一种,将非数值的单词嵌入到向量空间中去.也就是赋予每个单词一个向量.而以前谈到的t-sne的也是一种流形嵌入是将高维数据嵌入到低维空间中
谈论的要点
- 为什么要进行词嵌入
- 模型背后的思路及如何训练模型
- 实现一个简单的模型
- 完善模型
为什么做单词嵌入
词向量空间模型(VSM)是将一个单词在一个连续向量空间的映射.相似的单词在向量空间的映射点是相邻的.
VSM在自然语言处理(NLP)中有很长的发展历史.一般都基于一个分布假设,该假设是在同一上下文总出现的单词分享同样的语义. 从方法的本质上有分为两类.
- 基于计数的方法. 如隐含语义分析(Latent Semantic Analysis)
- 预测模型的方法. 如神经概率语言模型(neural probabilistic language models)
上面这两种分类明确说明在Baroni et al的文章中.
简要来说
- 基于计数的方法是计算单词和相邻单词在文档库中共同出现的频率的统计信息,然后将每一个单词映射到向量空间
- 预测模型是从单词的相邻单词直接尝试去预测一个单词, 单词向量化的信息最后实际上表示为模型的参数
word2vec
而词向量Word2vec是一种从原始文本中学习到单词嵌入向量的,能高效计算的,预测模型.
word2vec又有两种形式
- CBOW Continuous Bag-of-Words model
- Skip-Gram model
先上一张模型的结构图
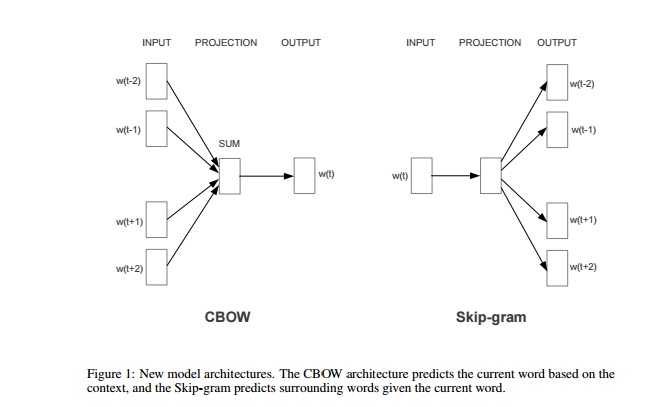
上图来自于Tomas Mikolov et at的Paper.
Skip-Gram 模型
一句话的简要描述, 给定一个单词序列$w_1, w_2, …, w_T$, Skip-Gram模型的目标就是最大化下面的平均对数概率.
对于基本的Skip-Gram模型,使用softmax函数将概率$p(w_{t+j} \vert w_t)$定义如下
关于优化过程, 由于使用了softmax函数,在做概率归一化是需要计算词汇表中每个单词作为上下文中单词的概率. 和NNLM中遇到的问题一样,计算量相当的大. word2vec采用了一种简化版的Noise Contrast Estimation技术来处理这个问题,称之为负采样(negative sampling). 正如作者声称的一样, 这个思路和C&W模型处理softmax计算量过大的思路一致. 也就是将目标词从噪声词区分出来(Ranking up from noise words).
目标函数
本质上NCE是近似地最大化softmax的对数概率,简化版的负采样定义优化目标函数如下
$\sigma(x) = \frac{1}{1+e^{-x}}$是逻辑函数.本质上,目标函数的第一项,就是类似二分类的逻辑回归,但是所有的训练样本都是正样本. 而负样本来自于对噪声词的采样.也就是目标函数的第二项. $P_n(W)$为噪声词的分布, k为采样的个数,都是模型的超参.
按照Mikolov的paper中描述, 当使用大数据集时,k的值可以取小一点,建议是2~5, 而噪声词的分布模型的选择,在paper中指出采用the unigram distribution U(W) raised to the 3/4rd power也就是$\frac{U(W)^{3/4}}{Z}$的性能比unigram distribution要好. unigram distribution指一元(单个)单词计数分布. 在实现中需建立单词表并对每个单词在总文本中出现次数进行计数. 对计数值要计算3/4的指数,最后对所有单词的数值求和得到Z进行归一化. 对归一化后的概率分布计算cdf,然后用均匀分布产生随机数后从cdf得到样本
目标函数的梯度
模型中实际上有两个词向量表, 输入词向量表$v$和输出词向量表$v^\prime$,在训练过程中要对两个词向量表计算梯度和更新.
对输出词向量的更新, 用NN模型表述就是隐单元的权重
对输入词向量的更新
总结
关于整个算法的总结
- 建立词汇表, 并统计各单词出现次数
- 用各单词的统计次数建立噪声词的unigram cdf的表, 用于采样噪声词,
- 初始化两个词向量表, 一个为输入词向量表, 对于sg模型来说就是中心词的词向量表, 另一个词向量表为隐藏层的权重词向量表
- 根据窗口的长度对文档中句子扫描得到若干中心词和上下文单词的二元组, 对每一个二元单词组(对),进行训练
对每一个二元单词组(对)进行训练的过程如下
- 对上下文单词,用采样得到k个噪声词, 一共k+1个单词.
- 对上述k+1的单词,从相应隐藏层的权重词向量表取到对应的词向量
- 对中心单词,从相应的输入词向量表渠道对应的词向量
- 计算目标函数的对上下文单词,噪声词和中心词的梯度
- 更新隐藏层的权重词向量表中上下文单词和噪声词的词向量
- 更新输入向量表中输入(中心)词的词向量
在更新词向量时,由于是要最大化目标函数,所以是相加.
本质上word2vec是一种online版的matrix factorization. 而2014年stanford发布的GloVe就是直接基于单词统计信息的matrix factorization, GloVe整体训练更快一些,性能也很好
使用word2vec, 最后实际会得到两个词向量表,有文章认为可以去两个词向量表的平均.
关于word2vec性能的评估方法本文没有说明,可以参考相应的paper,有一种方法是给定2个单词来表达某种关系,然后给定第3个单词,而任务是根据关系和第3个单词来查询第4个单词. 譬如 france paris (给定关系) sweden (查询词) 正确的结果应当是stockholm, 具体的做法是计算关系词的距离,查询词加上距离得到一个向量,找到离这个向量最近的词向量为结果单词. 我记得距离好像是用的余弦距离.
参考
- [1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
- [2] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
- [3] Optimizing word2vec in gensim, http://radimrehurek.com/2013/09/word2vec-in-python-part-two-optimizing/