NNLM introduction
神经网络语言模型
概述
网络语言模型是词向量是嵌入技术的一种,将非数值的单词嵌入到向量空间中去. 该模型属于预测语言模型, 即通过完成一个预测任务,如根据一部分文本或单词预测与其相关联的单词,训练的过程中得到单词的向量表达形式.
NNLM
先看一下结构图
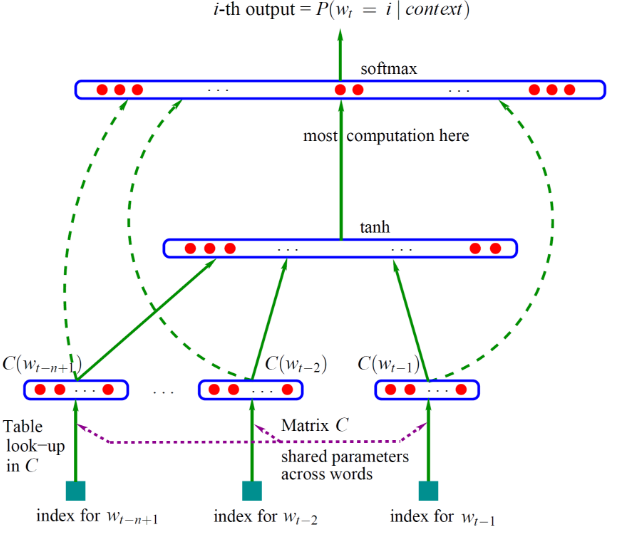
根据文档中连续出现的3个单词,预测第4个单词
初始化部分
- 对所有的文档提取单词制作词汇表,每个单词有一个唯一索引
- 模型参数的初始化,除了神经网络的连接权重初始化之外,还需初始化一张词汇嵌入向量表,该表的size为 vocabulary_size x dimension_size, 就是词汇表的长度和词向量每个向量的维度
前向部分
- 从文档中提取模型的输入,输入为3个单词的索引.
- 模型输入3个单词的索引,对每个单词的索引进行查表,得到每个单词的词向量, 假设我们想要想1个单词转换为1个50维的向量,此时3个单词就转换为3个向量,每个向量为50维.
- 将3个50维的向量作为输入一共是150维的向量作为输入,传送给隐藏层。
- 对于隐藏层每个神经元,150维输入乘以与神经元的连接的权重,求和后输入给激活函数,激活函数可以为sigmoid或tanh
- 激活函数的输出,作为输出层(softmax)的输入,假设隐藏层的神经元数量为300个,这就个300维的向量
- softmax层的单元数量为词汇表的长度,每个单元对,输入300维的向量乘以与输出层连接的权重求和,并计算某个单元输出的概率即 i为第i个softmax单元,x为输入,这里在例子中为300维向量,为隐藏层与softmax层的连接权重, 对于第i个softmax单元,权重为1个300维向量,转置后与输入相乘.
- 每一个softmax单元的输出为一个概率值,指示在词汇表中第i个单词为第4个单词的概率.
- 整个softmax的输出为应当为一个长度为词汇表长度的概率分布,其和应当为1.所以需要做归一化.即每个softmax单元的输出要除以softmax输出单元之总和.
反向部分
- 计算softmax的代价函数,用softmax的输出向量与真实的第4个单词的1-hot向量的
- 使用backpropagation,即一层一层的求出网络连接的偏导数,并使用梯度下降,更新网络连接权重参数
- 对词向量层也需要求偏导数梯度下降来更新词向量表. 整个过程反复迭代,而词向量表就得到不断的更新
注:
实际使用中隐藏层和softmax的输入还要加上一个bias,即每个向量追加一个常数1. 训练过程大多使用mini-batch方式进行梯度下降.
问题:
使用softmax做多类分类的任务,当词汇表相当大时整个模型训练的代价相当的大. 一个解决的思路是转softmax的多类分类为二分类,即是或不是的问题
Collobert & Weston model
先看一下结构图
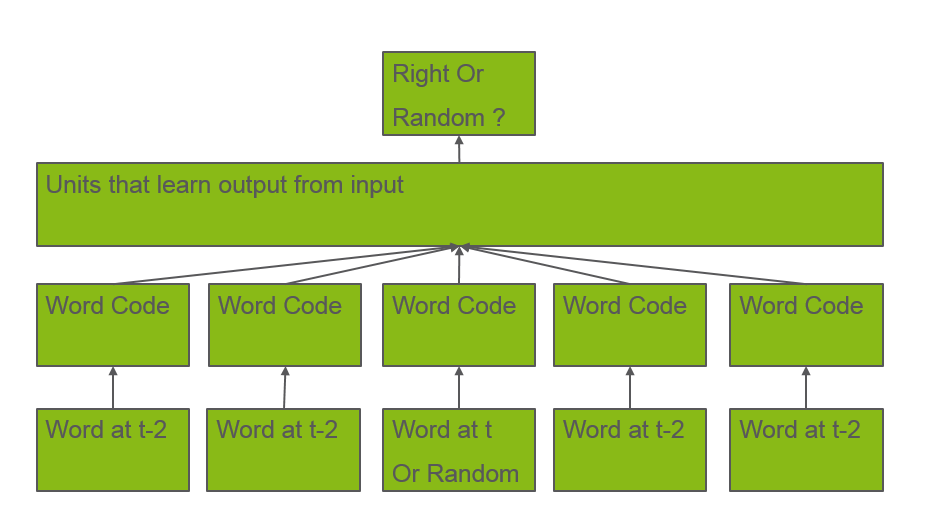
转softmax多类分类问题,为二分类
取连续5个单词,转成词向量输入网络中,作为正样本,将中间词替换为一个词汇表中随机选择的单词,转成词向量,作为负样本,网络的训练目标是区分出这是中间词是真实的还是随机的.
思路就是将词与噪声词区分开. Ranking up the word from noise words.
CW模型激活函数使用了HardTanh
后来CW模型演变成SENNA
参考
http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.149.8551&rep=rep1&type=pdf